Plot ZipCode Boundaries on a Map: Part 2 - Import Zip Code (U.S. Census ZCTA) Data Into A Database
Now that we’ve Made Sense of the U.S. Census ZCTA ARC/INFO Ungenerate (ASCII) files in Part 1 of this series, we are ready to import the U.S Census ZCTA Zip Code data into a database. In Part 2, we’ll create database tables and import the Zip Code Boundary data into those tables in a MS SQL 2005 database.
Create SQL 2005/2008 Database Tables
First lets create a couple database tables to hold all the Zip Code boundary data. One table will hold the ZipCodes, the other will hold all the Boundary Points for each Zip Code.
The table scheme is as follows:
ZipCode ID - uniqueidentifier ZipCode - char(5)
ZipCodeBoundary ID - uniqueidentifier ZipCodeID - uniqueidentifier IslandID - int Latitude - float Longitude - float SortOrder - int
Here’s a couple things to not about the ZipCodeBoundary talble:
- The *IslandID* field numbers each "island" or "zone" for that spefic zipcode's boundary. An island is an area within the zipcode that is omitted from the zipcode, or an island of land that is to be included within the zipcode that doens't physically thouch the main part of the boundary. The main boundary is going to have an IslandID value of 0 (zero).
- The *SortOrder *field numbers each boundary row in the order they appeared in the ARC/INFO Ungenerate (ASCII) file.
Here’s the SQL code for creating these tables. For this article, I created these tables in a database named ZipCodeBoundaries.
USE [ZipCodeBoundaries]
GO
/****** Object: Table [dbo].[ZipCode] Script Date: 06/24/2008 15:40:28 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[ZipCode](
[ID] [uniqueidentifier] NOT NULL,
[ZipCode] [char](5) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
CONSTRAINT [PK_ZipCode] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
/****** Object: Table [dbo].[ZipCodeBoundary] Script Date: 06/24/2008 15:40:43 ******/
CREATE TABLE [dbo].[ZipCodeBoundary](
[ID] [uniqueidentifier] NOT NULL,
[ZipCodeID] [uniqueidentifier] NOT NULL,
[IslandID] [int] NULL,
[Latitude] [float] NULL,
[Longitude] [float] NULL,
[SortOrder] [int] NULL,
CONSTRAINT [PK_ZipCodeBoundary] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Import Data Into Database Tables
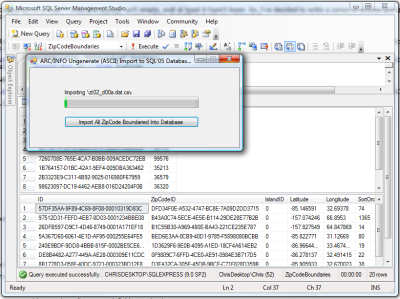 To make things easier, I wrote a small utility that reads in the “a.dat.csv” and “.dat.csv” files generated in Part 1 of this series and imports the data into the table defined above. One thing to note when importing the data from these file (and the original ARC/INFO Ungenerate (ASCII) files) is that each set of files starts numbering the ZipCodes at 1. So when importing into the database we much give each Zip Code a unique ID (in this article I’m using GUID’s for this) and setting that ID correctly for each of the Zip Code Boundary Points.
To make things easier, I wrote a small utility that reads in the “a.dat.csv” and “.dat.csv” files generated in Part 1 of this series and imports the data into the table defined above. One thing to note when importing the data from these file (and the original ARC/INFO Ungenerate (ASCII) files) is that each set of files starts numbering the ZipCodes at 1. So when importing into the database we much give each Zip Code a unique ID (in this article I’m using GUID’s for this) and setting that ID correctly for each of the Zip Code Boundary Points.
Download the Import Utility: ImportARCINFOASCIIToSql05Database.zip (15.18 kb)
Remember, that when running this utility, it can take awhile to import ALL the ZipCode Boundary data for the entire country.
Note, this example utility has the connection string hard coded in the Form1.cs code file. Don’t forget to change it to point to your database, unless you create your database on the local SQL Express instance and name it “ZipCodeBoundaries” like I do in this article.
Prev Part: Part 1 - Making sense of U.S. Census ZCTA ARC/INFO Ungenerate (ASCII) files
Recent Posts
-
C#: Console App that Accepts Command-Line Arguments
23 Apr 2024 -
C#: How to iterate over a dictionary?
20 Apr 2024 -
C#: What is the difference between 'string' and System.String?
16 Apr 2024 -
Include Javascript File in Another Javascript File
22 Mar 2024 -
Javascript: How Closures Work
22 Mar 2024



