CQRS: Command Query Responsibility Segregation Design Pattern
Jun 15, 2014 • Design PatternsI was recently turned onto the Command Query Responsibility Segregation (CQRS) design pattern by a co-worker. One of the biggest benefits of CQRS is that is aids in implementing distributed, highly scalable system. This notion can be intimidating, but at the heart of CQRS there are rather simple guidelines to follow. Now let’s dive in and explore what this pattern is and some way of implementing it.
Purpose of Command Query Responsibility Segregation (CQRS)
The main purpose of CQRS is to assist in building high performance, scalable systems with large amounts of data.
Derives from Command Query Separation (CQS)
The basis for the CQRS pattern is the Command Query Separation (CQS) design pattern devised by Bertrand Meyer. The pattern states there should be complete separation between “command” methods that perform actions and “query” methods that return data.
Here’s a really simplistic object oriented example of Command Query Separation in C#:
// Simple CQS Example
public class DataStore {
// Query Method
public Person GetPerson(int id) {
// query data storage for specific Person by Id
// return Person
}
// Command Methods
public void Insert(Person p) {
// Insert Person into data storage
}
public void UpdateName(int id, string name) {
// Find Person in data storage by Id
// Update the name for this Person within the data storage
}
}
The above example has clear separation between the Query method “GetPerson” that retrieves data, and the Command methods that insert or update data.
Adding Responsibility Segregation
Next, CQRS takes “Separation” from CQS and turns it into “Segregation” to completely pull apart the Responsibilities of Command and Query methods to place them in separate contexts.
Here’s a simple example in C# of taking the above CQS example and adding the “Responsibility Segregation” concept to it:
// Responsibility Segregation Example
public class QueryDataStore {
public Person GetPerson(int id) {
// query data storage for specific Person by Id
// return Person
}
}
public class CommandDataStore {
public void Insert(Person p) {
// Insert Person into data storage
}
public void UpdateName(int id, string name) {
// Find Person in data storage by Id
// Update the name for this Person within the data storage
}
}
The seemingly simple change to completely separate Command and Query methods has some fairly big implications on the way you implement the Command and Query methods themselves. By breaking them apart to completely separate contexts, they must be able to function in isolation, completely independent from each other. What this means is that the Command object in the above example must not have a hard dependency on the Query object. If they were to depend on each other, then the design would still be CQS instead of CQRS.
Here’s a simple diagram to help clarify the separation of Command and Query how it pertains to CQRS:
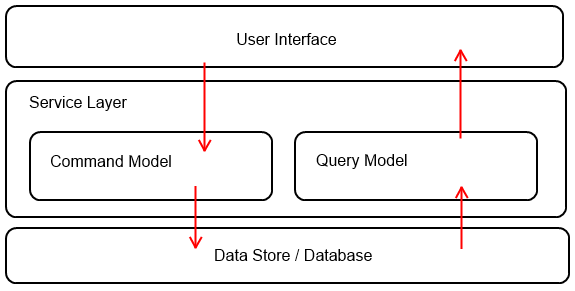
Separate Models for Command and Query
The way CQRS enforces Responsibility Segregation is by requiring there to be separate models used for Command methods than for Query methods. The above responsibility segregation methods example would then be built out so that the Query class and Command class can operate completely independently without either one having dependencies on the other. One of the key principles for this in CQRS is that the pattern is really meant to allow for there to be multiple Query and/or Command classes, each with it’s own methods, that get used when it’s unique circumstance require. For example, there may be a Query class for simple data retrieval with a separate Query class used for a more complex, power user search.
CQRS + Event Sourcing
Event Sourcing is a separate design pattern itself, but it is necessary to integrate with CQRS when building systems that have distributed data along with the requirement of high performance and scalability; as these are the systems that CQRS was really developed for. Event Souring allows the CQRS implementation to have a separate data store (or database) for consistent, stable data with change tracking, while easily maintaining separate data stores (or databases) that have eventual consistency.
Here’s some example breakouts of systems that would benefit from a CQRS plus Event Sourcing architecture:
- A system that has the main database used for editing data, and a separate Reporting database that is synced with eventual consistency.
- A system that has the main database used for editing, with a separate database used for extremely specific query operations where searching and reporting have their own data models to facilitate higher query performance.
Here’s a simple diagram to help clarify how CQRS can be combined with Event Sourcing:
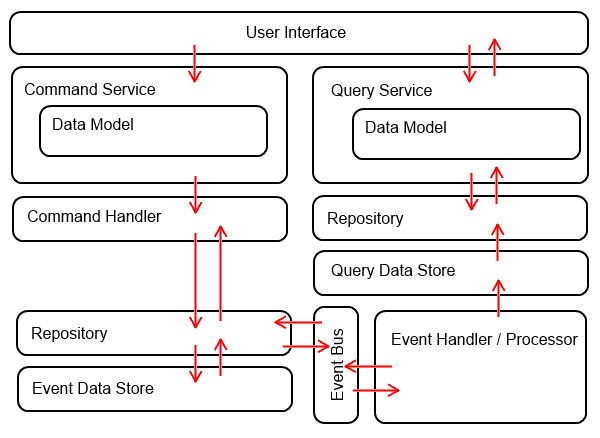
It is important to remember that Event Sourcing is not a requirement of CQRS unless the system architecture is utilizing distributed data. Event Sourcing gives the system the ability to maintain eventual consistency of the Query models while maintaining the Command model as the source of that consistency. Without Event Sourcing there really isn’t any way to effectively build a system using CQRS and Distributed Data.
Single Database for both Command and Query
Just because you have separate models for Command methods than Query methods doesn’t mean the data can’t be stored and queried in the same place. This is just an implementation detail for you to decide when using the pattern; however, the biggest benefits of CQRS come when using it to maintain completely separate data stores for Writing data (Command) than for Reading data (Query.) CQRS is really meant to be used for building systems with distributed data, and high performance and scalability.
New Paradigm in System Design
There’s a bit of mysticism in the industry as to what CQRS is. Some say it’s a philosophy and not even an architectural pattern. Before writing this article, I read through various different opinions on what CQRS is and how it relates to Event Sourcing. I have come to the conclusion that CQRS is an extremely simple design pattern, just as all design patterns should be. However, the level of abstraction that it facilitates really creates a huge shift in the way that software systems work with data. Instead of designing a single data access layer that utilizes a single, traditional data store, CQRS opens software architecture up to a new paradigm. This new paradigm breaks the software free from the restrictiveness of the vertical, monolithic data store thus allowing for the data store to be built in a similar modular fashion as the way clean code is. CQRS facilitates the storage, retrieval and editing of distributed data.
While the paradigm shift of distributed data is still fairly new to the software industry, it is most definitely the direction that things are moving. The “No SQL” movement of recent years is a testament to the fact that developers and architects abound are discovering the need to more effectively handle large amounts of data in a distributed fashion that allows for much greater flexibility and scalability.


Recent Posts
-
Adapt as an AI Developer of Be Left Behind
20 Mar 2025 -
Power of Small Wins: Consistency Beats Perfection
03 Mar 2025 -
Control AI, or Be Replaced By Someone Who Does
03 Mar 2025 -
Resetting Identity Seed in SQL Server After Deleting Records
03 Feb 2025 -
Distributed Social Media Is the Future: A Shift Away from Centralized Platforms Like Facebook and TikTok
19 Jan 2025
Recent on Build5Nines.com




